A canonical tag is a snippet of HTML code that is used to tell the search engines that a URL is the original copy of a webpage when multiple version of the similar content exist within the website. It helps in consolidating the similar content under original URL and through this avoid the duplicate content issues within the website. This ensure better SEO performance in the search engine results.
Duplicate content is a major issue in SEO when search engine crawlers crawl many URLs with similar content. If crawlers see these duplicate content, then there is a chance to miss the original content. Moreover, large number of duplication may dilute the ranking and may be penalties in some cases.
Even if your content is ranking on search engine, then search engine may choose the wrong URL as the original. So, Canonicalization helps you control the variations of a single webpage with single original page.
Read more: How to add Google Tag Manager in WordPress. Click on the below link:
The problem is that as humans, we tend to think of a page as a concept, such as the homepage. But for the search engines, every unique URL is a separate page.
Let’s have a look on the given URLs:
For humans all the above URLs represent the single page. But in the case of the crawler, every single URL represents the different page. Even there are 3 copies of the homepage in the limited example.
Nowadays, content management systems (CMS) are very common for blogging, ecommerce websites. Many CMS websites automatically add the tags, allowing multiple paths to the same URLs. You may have thousands of duplicate URLs on your website and you may not even realize it.
Now the query is why would anyone make a duplicate or similar page? and think that there is no need to worry about the canonicalization. The main issue is we think a page as a concept. But for search engines, each unique page is separate page of the website.
For example, search engine crawlers may reach your homepage by many ways. Some of the ways are:
For us as a human being, all the above URLs represent a homepage. But for the search engine crawlers, each page is a Unique page. There may be thousands number of duplicate pages on the website and we don’t even realize it.
It’s really tricky to handle the duplicate content issues, but here are a few important things to consider while using the canonical tag:
Some of the points to consider while using canonical tag on the webpage are:
It is fine, if the canonical tag points to the same URL. For example, if URLs D, E, and F are duplicates, and D is the original version of that pages, then it is required to put the canonical tag to the D on URL D. This sounds clear, but sometimes it creates confusion.
Duplicate homepage are very common mistake that people can link the homepage in many different ways. So, it is a good ides to put canonical tag on the homepage to avoid the duplication error.
A few bad codes cause a website to write a different canonical tag for each version of the webpage. So, check the URLs, especially on e-commerce and CMS websites.
Search engines ignore the canonical tag if you send the mixed signals. In simple words, Avoid canonicalize page B> page C and then page c> page B.
Similarly, Avoid canonicalize page B>page C and then 301 redirect page C > page B. You should also ignore the chain canonical tags (C>D, D>E, E>F). By using this mixed signal you are forcing search engines to make a bad choice. So, try to send the clear signals to the search engine.
One most common doubt is whether canonical tags pass the link equity (Authority) like 301 redirects. And the answer is no, these two create totally different results for the search engine bots and users.
If you redirect Page C> Page D, then the users will land to Page D automatically and never see Page C.
And if canonical Page C> Page D, then the search engine will know that Page D is canonical, and the users will visit both the URLs.
There are a number of ways for checking the canonical tags. Here is the list:
A common mistake is to point the canonical at a URL that is either blocked by robots.txt, or is set to “noindex”. This can send mixed and confusing signals to search engines. A few common ways to inspect and audit your canonical tags are below.
Sometimes the canonical URL is blocked by robots.txt or it is set to robots meta “noindex”. It send mixed signals to the search engines. Below are a few ways to audit the canonical tags (canonicalization).
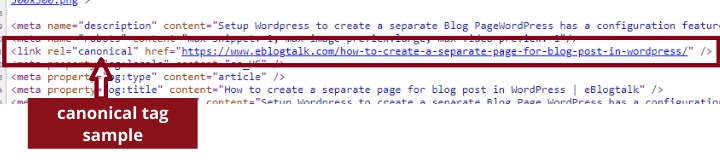
You can simply right click to view-source in most of the browsers or type view-source:https://www.eblogtalk.com into the address bar. And then search for the canonical tag in the head by (ctrl + F) and type canonical.
MozBar is a free SEO audit tool that show the canonical tag on the given webpage. You only have to click on the Page Analysis tab, then hit on the “General Attributes” to view the canonical.
This post was last modified on January 12, 2025
Are you searching for the top Linktree alternatives? You’re in the right place. Back in…
Ever thought about getting paid for your opinions? Yes, it’s real! You can earn money…
Looking to Get Paid To Watch Videos Online 2025? Not surprisingly, some of the applications…
Non-Governmental Organisations (NGO) is very important and they fill the gap which government agencies and…
What if you could get paid just to listen to music? Sounds unreal, right? But…
How often have you encountered marketing and sales tactics while purchasing goods online? Like: “Hosting…
This website uses cookies.
Privacy Policy
